Author Archive
Overblown Egg Timer, part 3
by TheWatcher on Apr.10, 2020, under General, Hardware
Part 1 covered the overview of what I wanted to achieve, while part 2 covered the construction of the hardware. In this third part I’ll give an overview of the software running on the Arduino to coordinate button presses and lights.
But first, some revised diagrams – in part 2 I found that using the D0 and D1 pins for communication with the Grove LED bar was a poor choice, and had to rework things to use D7 and D8. Here’s how that change looks in glorious technicolour diagram form (click to enbiggen):
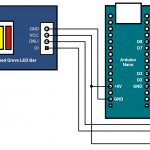
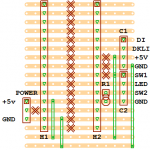
The software to support this project splits into roughly four pieces:
- The Arduino sketch (the core code to set up the board, and do something in a loop)
- Some code to control the LED in the illuminated switch button, and to read button presses
- Something to implement the overall behaviour of the system.
- The Grove LED Bar support library, used to control the LED bar
You can find the code for 1, 2, and 3 in this repository in GitHub. I also had to make a few changes to the Grove LED Bar library, and you can find that in this repository, also on GitHub. I won’t delve into the code here in any detail – there’s a lot of documentation in the code, and if you’re interested that will hopefully be sufficient to explain what’s going on in there – other than to note the correspondence between the above-noted code parts and the files in the repository that implement those parts:
- laundry.ino is the arduino sketch file. This contains the setup code, and the loop() function that fetches events from the switch control code, and passes them to the FSM.
- SwitchControl.h and SwitchControl.cpp contain the definition and implementation of a C++ class that handles communication with the push button switch and its illumination LED.
- FSM.h and FSM.cpp contain the ‘brains’ of the project, the Finite-State Machine and the implementation of the various states the system can be in.
Adventures with Arduino (pt 2)
by TheWatcher on Mar.25, 2020, under General, Hardware
In part 1 I outlined the general – if crazy – idea I intend to attempt. In this part, I’m getting down to actual hardware – starting with the switch and illumination LED I left off at in part 1.

The switch I ended up buying was a RJS-K16-291-GE-65J , a momentary push-button switch with a green illuminated button that is lit up using a LED set up for use with a 12V supply. This is, as previously noted, less than ideal for use with the 5V supply used by the Arduino Nano – so the first thing to do is take the switch apart to see how easy it might be to replace the resistor or the LED assembly with something more suitable.

The datasheet for the switch isn’t entirely helpful about how the switch goes together, so I approached the problem by the tried and true method of pulling on bits until something gives. Thankfully, the green button actuator pulls off to reveal the LED module behind it.

Less helpfully, the LED module has the resistor built-in, and it is a pretty-much sealed unit – this is the little green module at the bottom of the picture to the left. I couldn’t work out a way to get inside without irreparably damaging it, so I decided it’d be best to just replace the whole thing, and solder the current limiting resistor to the contact on the back of the switch rather than inside it.
(continue reading…)And now for something completely different (pt 1)
by TheWatcher on Mar.19, 2020, under General, Hardware
And by “different”, I obviously mean “anything at all”. Normally I wouldn’t write up something like this – which part of the reason this site gets updated so infrequently – but right now I’m not burning a chunk of the day commuting, so what the heck…
Back in the ancient and near-forgotten times of the last days of 2019, our venerable washer-dryer stopped working. This was honestly not overly surprising for a device nearly nine and a half years old, but it was… inconvenient, at the very least. Better yet, it wasn’t showing any error codes! It would simply refuse to run any programs with an “Err” message. In order to find out what was really happening I had to put it into a maintenance diagnostic mode, where it finally gave an error code… except it was an error code that doesn’t appear in the manual! After much consultation with the great Internet Oracle I determined that the error was trying to tell me that either the heater element was out, the heater relay was broken, or that the deep state had infiltrated our lives in a subtle plan to use our washer-dryer as a portal for alien overlords.
Upon opening it up and applying lots of cursing I discovered the real culprit: the relay was fine, as was the heater, but a SMD diode was blown, and a corroded track on the main board had broken. And no trace of aliens, either. I was able to replace the diode with an equivalent scavenged from another old board I had in my pile of it-might-come-in-handy-some-day parts, and solder in a wire to bridge the damaged track, but the machine was obviously not much longer for this world. After much intensive research by my better three-quarters, we bought a new machine and awaited its delivery with baited breath.
And it works great, does a good job, except for one issue: it turns itself off a few minutes after it has finished a program. When the old machine finished a program, it would leave the display on and you could tell there was stuff in there that needed to be taken out… the new one, in the name of power efficiency, doesn’t do that and that has lead to things being forgotten in the machine for hours. Normal timers aren’t useful, because they go off and might be ignored at the time, and then forgotten about.
So, I’ve decided to build something a bit more in line with our needs.
The name of things
by TheWatcher on Dec.27, 2013, under General
Yes, I really suck at this thing. I blame the fact that the Earth spins too rapidly, inconsiderate ball of damp rock.
A couple of days ago someone mentioned the (broken) behaviour of a system they developed when people are added to it, but their names do not confirm to an expected format. This reminded me that a while ago a fellow member of the Secret Cabal of Shadowy Associates linked me to a blog post about programmer’s misconceptions and errors when dealing with names, specifically names of individuals. The entire thing actually irritated the everliving crap out of me: it is a prime example of a smug bastard saying “here’s a problem I’ve identified, and I know how to solve it… but I’m not going to tell you how! Aren’t I awesome?” ((My initial reaction to it was ‘”[I] have theoretically designed [whatever that means] their systems to allow all names to work in them” – Okay genius, how? Share your wisdom with us lesser mortals!))
Part of the problem is that, at the root of it, he’s technically correct: most systems you’ll run into have a horribly westernised concept of given and family names (forenames/surnames, whatever you want to call them) that falls down the instant the system has to deal with non-WEIRD individuals. Working for a university, I constantly run into cases where students with names that do not conform to the traditional western scheme have been kludged into systems that enforce it ((Embarrassingly, one of these is a very old system I developed before I was Enlighened. Some day I hope to go back and fix that thing…)). That blog author takes things to extremes, and if all his statements are taken as accurate, there is pretty much no way to realistically create a system that handles all of them sensibly. But it is quite possible to cover the majority of issues, and unlike the blog post linked, I am going to actually give some thoughts about ways to handle these things in real situations.
For a start, use Unicode: at the very least UTF-8 is widely supported either directly or via libraries in pretty much every language worth using (and several that aren’t, like PHP). If you’re still using ISO/IEC 8859-* and similar single-byte character encodings your code is broken. Seriously. You’re not doing anyone any favours holding onto that shit. Your code may work fine for very specific situations, it may even work fine most of the time, but for anything but toy programs you will eventually run into cases where you simply can not handle some characters, and fixing it will be an unholy mess of kludges and spiders. Avoid it from the beginning; use Unicode throughout.
Next, give up on the concept of given names and family names. Do not attempt to split the name data along any seemingly ‘sensible’ lines: there will inevitably be a naming scheme out there that will not work with your rules. Yes, this sort of thing will be entirely contrary to years of conventional western wisdom, and it means that things like sorting by last name don’t work – but if the individual has no last name (yes, it does happen), or comes from a culture that reverses or discards the forenames-followed-by-surname idiom ((While collaborating with some Japanese developers some years ago, I spent a lot of time being referred to as Mr Chris because of this…)), that sorting would be invalid, or at least inaccurate, either way.
Do not simply assume that names will only ever consist of simple alphabetic characters, either. Hyphens and apostrophes are widely used even in western names, but some cultures can use a variety of other punctuation marks in names (and not just the ones commonly found on western keyboards!) Limiting the characters the user can input is artificial and undermines the whole point of trying to be better at supporting names: sanitise the input before you use it ((Which you’re doing with all your input, right?)), but don’t artificially limit it.
These steps will handle the vast majority of names out there. Searching and sorting are trickier, but storing an individual’s name in one UTF-8 encoded string means that pretty much every language and cultural naming scheme will work. Allow for optional names, and you can handle even the most weird edge-cases.
So, housekeeping
by TheWatcher on Jul.08, 2013, under General
In a vague effort to keep this page from being utterly dead, I’m moving my dev blog (which is not quite dead… it’s getting better…) to the front of the site, replacing the old starforge primary website. I’m undecided about whether I will change the theme to something closer to the previous site, but for now I’m leaving it as it is in the vague hope of actually doing useful stuff elsewhere rather than faffing around with themes.
So, on that note, onwards!
Paswords… *sigh*
by TheWatcher on Feb.04, 2013, under Perl, Web devel
So, one thing I’m currently dealing with is the handling of user account passwords. Not the storing of said passwords (or rather, salted hashes of them) – that part is actually really easy: push it through Crypt::Eksblowfish::BCrypt‘s bcrypt() function with a randomly generated salt and decent cost (I use 14 at the moment, many sources I’ve seen recommend 10), store the result for later use in password validation.
No, the problem I’m dealing with is password policies. Originally I was considering just omitting any password policy enforcement – everyone has seen jokes along the lines of
13:11 <@froztbyte> <@gamajun> "Your password needs to contain a capital letter, a number, an emoji, and a plot containing a protagonist and a twisted ending."
and some of the ones out there are, frankly, nearly that level of utterly ridiculous. Not only do these policies make it much harder for users to deal with passwords, they can actually make attacks easier – in part they can reduce the search space needed, and when combined with some knowledge of human behaviour, you can get a pretty good handle on the general format of passwords people will use. ((I had a much longer rant ready for here, but really it’s not worth carrying on about it – just assume that I’m in the camp of people who think that password policies are potentially dangerous simply because of the false sense of security they can engender.))
There are things that can be done to mitigate some problems – lock out users after a number of login failures to prevent brute-force guessing attacks, and ensure stored passwords are salted and hashed using a high cost algorithm in case the database itself is compromised – but policies are far from the panacea some security ‘experts’ seem to think they are.
12 years of dealing with real-world functionally-computer-illiterate users (irony being, many of them work in a university Computer Science department) and their approach to password security has pretty much convinced me that relying solely on passwords to provide anything beyond a modicum of security is hilarious naive and ultimately doomed. But that said, passwords are an established convention, and more or less the only remotely convenient (if not viable) option in most situations – so in the end I decided that some support for policy enforcement would be useful. If nothing else, it gives some people a fuzzy feeling, and I’ll almost certainly end up being asked for it anyway. The thing that needs deciding after that is just what can be dictated…
There are the obvious things, like the number of characters required and the composition of the password as in the example above. Those can be specified as a series of minimums for each auth method ((Although, for the moment, only Webperl::AuthMethod::Database will actually make use of it – the other auth methods do no support password changes, so they don’t need to enforce policies)), where if no value is set there is no minimum, no policy regarding it:
policy_min_length, passwords must be at least this number of characters long.policy_min_lowercase, at least this number of lowercase characters must be present.policy_min_uppercase, at least this many uppercase characters must be included.policy_min_digits, the minimum number of digits that must be used.policy_min_other, the number of non-alphanumeric characters that must be present.
There are other options, though: one is to invoke cracklib via Crypt::Cracklib and let it judge the password’s quality, rejecting passwords that do not pass muster (something that’s probably a good idea, regardless of policy, really). Another option is to calculate the password’s entropy, and reject passwords with entropy below a set threshold. There is at least one perl module to do this – Data::Password::Entropy – and it seems mostly decent, although it appears to produce somewhat more generous values for some test passwords than Tyler Akins’ Strength Test calculator. I’ve decided I may as well allow them as options, so:
policy_use_cracklib, if true, the password is checked using cracklib to determine whether it is acceotable.policy_min_entropy, passwords must have at least this entropy to be considered strong enough
Now I just need to set about documenting these well enough, including some decent scales for the entropy. The Strength Test page linked above has some recommendations for entropy ranges for different strengths of password, but as I say Data::Password::Entropy generates slightly higher results, so I will need to do some testing to provide decent recommendations.
Oh, yeah, and I need to actually code this stuff. I might actually get to do that if things would stop breaking…
The coalface
by TheWatcher on Jan.18, 2013, under Perl, Web devel
I’ve said what I’m not doing, but not yet said what I am. I suppose I should do something about that.
Ignoring work for now[1], my current focus is on something called Project Eyeshine, the working title for a photo and video gallery webapp that I’m writing in Perl. Why does the world need another web gallery system, you ask? Buggered if I know what the world wants, but I know my wife and I want one that isn’t crap… and guess what all the web gallery systems out there are? Why yes, they are indeed all crap. I have spent entirely too long trawling through alternatives, and they range from the just-about tolerable to things resembling the collected unholy, festering scrapings from the bottoms of a thousand diarrhoetic devils. None of them are actually good. They either look ghastly, are painfully broken in places, have bizarre and ridiculous dependencies and system requirements, lack important features, seem to have been developed by people besotted with shiny features at the expense of actually useful stuff, or generally appear to have been coded by someone who was teaching themselves PHP as their first language while trying to find every bad practice and security risk they could. This, frankly, will not do.
I’ve made a fair amount of progress, even though I’ve only been working on it since just before Christmas, but in reality a lot of the progress hasn’t been directly on the system itself: it’s been in the framework of classes that sit beneath it (more specifically, improving the implementation of the authentication code to handle auth systems that don’t support password reset, and speeding up parts of the template handling). This framework, imaginatively called Webperl, is another one of my perennial projects – a library of classes and modules intended to simplify the process of developing web applications in Perl. Why does the world want another one of them as well? Well…
- This is Perl: “There’s More Than One Way To Do It” is its motto.
- This is Perl: a very large amount of the code out there is horrible, unreadable, madness-inducing spaghetti lacking any real attempt at code documentation. I don’t write code like that[2].
- Each framework, explicitly or implicitly, tends to impose a specific approach on the developer using it (whether the creators of it admit it or not), which may or may not be the way things work in the developer’s head.
- Most of the web frameworks available when I started this thing (some 10 years ago!) were either too simplistic to be useful, too buggy to be reliable, or so complicated it was faster to write something from scratch than work out how the devil to use them.
The latter point is something that has simply become more pronounced over the years, culminating in things like Catalyst, a framework that eschews such piffling simplicities as including a kitchen sink, instead giving you a dozen different modules for different variations of kitchen sink components (well, actually, more like 500 modules) and expecting you to put them together.
Webperl isn’t intended to be immensely powerful and complicated. It doesn’t do a fraction of the things you can in Catalyst, very intentionally so – if you want that level of power, use Catalyst! But that’s not to say it isn’t decently capable: it is used in half a dozen major projects in work, including running the registration, submission, shortlisting, and judging for a national competition with nearly a thousand entries per year. The key for me is balancing the features the system provides with making it actually usable.
So, yes – a lot of what is likely to appear on here in the nearish future is going to concern either Project Eyeshine, or changes made to Webperl. Hopefully soon, I’ll even be able to link the former so people can poke at it…
[1] not exactly straightforward to do, as much of the stuff I’m doing out of work can actually be repurposed for work, and vice versa!
[2] which I freely admit sounds quite ridiculously stuck up, pompous, snobbish, and self-deceiving, but it’s also frankly true. On any given project, I generally have over 35% of my code given over to comments, webperl is 54.4% comment – and that’s excluding standalone documentation. I react to the “Perl is a write-only language” meme by explicitly setting out to prove it wrong.
State of development
by TheWatcher on Jan.13, 2013, under General
So, yes. Apparently I suck at this stuff – when I said, “Now we just need to see whether I actually keep this up, or whether I get a handful of posts in and forget about it,” I honestly did expect to make at least a handful of posts, not two and then let this sit unused for 9 months!
When I started this I had some clear ideas about what I wanted to start working on, and even some c and c++ code to get going with. Then Life happened, and other project got priority, and for a while I considered posting here about stuff I was working on… except that I originally intended this to be purely for the OpenGL projects I wanted to work on, and didn’t want to post about the rest.
I’ve decided that doing things that way is ultimately going to leave this thing stagnant for even longer, as there are Things I Need To Do, and none of them currently involve OGL at all. Whatever I originally intended, I’m going to treat this as a general dev blog, and post about things I’m currently working on rather than leave it unused.
Amativ alok, and all that…
OpenGL…
by TheWatcher on Apr.14, 2012, under OpenGL
In the beginning, there was OpenGL 1. It didn’t even have the ‘1’ back then, it was just OpenGL. It was fairly basic, it had ‘Immediate Mode’, where you told it what you wanted it to draw as you went along, and a “Retained Mode” where you saved up a bunch of Immediate Mode instructions in display lists and told OpenGL to execute the contents of the display list when you needed it, or created arrays of data and had the system draw based on the contents of the arrays. The rendering pipeline was fixed, you turned on and off features as needed, and had to work within the constraints the pipeline imposed.
It was simple, generally easy to use, easy to understand. You could do a lot with it, and for some purposes it is still enough.
But as time passed, more features got bolted on in the form of ‘extensions’, until several of the most useful and commonly supported ones were squished into the standard, along with some new features, and OpenGL 2 was pushed blinking into the light of day. OpenGL 2 kept the fixed function pipeline, but introduced vertex shaders and fragment shaders, that optionally allowed you to replace chunks of the pipeline with completely programmable sections. If the standard, fixed pipeline couldn’t do something you wanted, or you could provide a faster, application-specific version? You could write shaders to do it – it combined the ease of use of OpenGL 1 with drastically more scope and power.
And then came OpenGL 3.
OpenGL 3 deprecated, and then removed, the fixed functionality, the immediate mode, and lots more on top. For people trying to squeeze the last drop of performance out of the graphics card – game programmers in particular – this didn’t even really register, as they’d already been using the features that were to be the future of OpenGL. But there are a lot of people out there that don’t fall into that camp – a lot of old software relies on the deprecated features, and the change turned OpenGL’s learning curve into a learning cliff. It also makes hammering out quick tests, or simple features that don’t need absolute speed but do need rapid development, a lot harder to pull off. A special “compatibility” mode was added to the specification, which allows the use of the old commands and pipeline (essentially, it’s OpenGL2), and the major 3D graphics card manufacturers have gone on record as saying that they do not intend to actually remove this compatibility mode.
This means that the old features are going to be there for the long term… but it has also meant is that, since the release of the OpenGL 3 spec in 2008, online tutorials and most books have practically been denying the deprecated features even exist (which I suppose is fair enough, as they are deprecated, but they do still serve a useful purpose, and make learning what you’re doing drastically easier).
What this means for me is mostly academic at the moment – I’m sat here with a GeForce 7900 from 2006, and I’m stuck with OpenGL 2.1 anyway. I’ll probably mostly be using features that haven’t been deprecated, too, so I might not even need to care… Eventually I will probably need to worry about OpenGL3 and 4’s changes, but for now I have a good reference for 2.1, and a fairly good idea of how to filter what I can find online…
(Yes, there is an OpenGL 4, but the changes that introduced are nowhere near as significant as the 2.1 to 3.0 changes, so I’m not including it here.)
You must be logged in to post a comment.